Lo mismo ocurre en los Data Centers. No siempre que se detectan problemas de temperaturas la solución es bajar la temperatura del CRAC. El problema también puede ser la presión de aire. Por lo tanto aumentar o reducir la velocidad de circulación del aire frío puede ser la solución óptima. En los diseños donde el aire frío ingresa por debajo del piso técnico, el pasillo frío debe estar libre de obstrucciones, permitiendo una circulación libre. Es por ello que los cables de alimentación y comunicaciones deberán pasar por debajo del pasillo caliente.

Para asegurar la correcta refrigeración de los equipos, una de las claves está en descargar la cantidad justa de aire frío, dirigida hacia la fuente de calor, mediante rejillas en el piso técnico o por ventilación superior.
En el caso del piso técnico, se produce un cambio de presión dentro del piso falso, comparado con la presión externa. En función de este diferencial, aumenta o disminuye la velocidad de giro de los ventiladores EC de los climatizadores. En caso de tener un solo un pasillo frío encapsulado, se mide el diferencial de presión del interior del pasillo con la sala, usando esta señal para regular la velocidad de giro de los ventiladores.
En el piso del pasillo encapsulado están los elementos de control de caudal de aire frío, en función de la temperatura dentro de los Rack. La presión en el interior del pasillo encapsulado no debe superar un valor máximo para no exigir a los ventiladores en el interior de los servidores. En caso de tener múltiples pasillos encapsulados, se instala una regulación por pasillo y una de presión general del
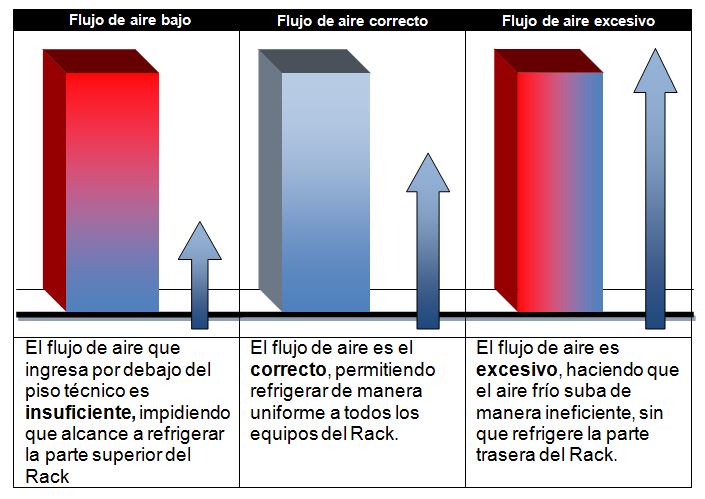
piso falso. Al reducir el caudal de aire a la mitad, el consumo eléctrico es mucho menor. A mayor velocidad de circulación del aire, menor presión estática en las placas perforadas más cercanas a la unidad CRAC. Dicho control asegura que el aire sea el justo y necesario, permitiendo un ahorro significativo en el consumo eléctrico de los ventiladores. A continuación, se pueden ver las diferencias que existen entre un flujo correcto de aire y otros incorrectos.
El control de presión en pasillo frío encapsulado asegura que el aire fluya correctamente y se mantenga separado el frío del caliente, asegurando que el aire caliente reingrese a la unidad de enfriamiento sin pérdidas. De ser posible es recomendado mover la refrigeración más cerca de la carga, lo que permitirá ahorrar en potencia total de ventilación y proporcionará un tiempo de reacción más rápido si varían las cargas de los equipos en los Racks.
La eliminación del aire caliente puede estar provista por canalizaciones especiales ubicadas en el techo, que pueden ser selladas o no, ya que el aire caliente siempre tiende a subir a fin de permitir la expulsión de ese aire caliente hacia el exterior o para volver a introducirlo en la unidad CRAC. Si la temperatura de salida del aire caliente aumenta al reingresar a la unidad CRAC, el esfuerzo para
enfriarlo será mayor, y viceversa. Por otro lado, existe un problema frecuente en los Data Centers, ya que muchas veces se mueven equipos de un Rack a otro, dejando espacios libres y no se toman medidas para evitar la recirculación de aire caliente hacia el frente del Rack.
Instalado paneles ciegos (o también llamados de obturación) se impide que el aire caliente recircule hacia la parte delantera del Rack donde se encuentra la toma de aire frío para los equipos, haciendo un buen aprovechamiento de la capacidad de refrigeración

La clave es encontrar un equilibrio justo para tener la humedad en un rango óptimo. Los paneles ciegos en los Racks ayudan a disminuir la circulación del aire, manteniendo los pasillos fríos y calientes separados.



